Co to jest model scoringowy i dlaczego potrzebujesz przynajmniej jednego?
Problem z wyborem spółek do inwestycji jest taki, że nie ma firm idealnych. Jedne będą generowały oszałamiające zyski, ale ich akcje będą przewartościowane. Inne papiery okażą się tanie, ale spółka będzie dramatycznie zadłużona. Gdzie indziej jeszcze fundamenty i cena mogą być w porządku, ale prognozy zyskowności zaczynają się walić. Wiele z tych wskaźników będzie się wykluczało, dlatego do gry powinien tu wejść dobry model scoringowy.
Model scoringowy to nic innego jak zestaw kryteriów wraz z oceną punktową przyznawaną każdemu ocenianemu parametrowi spółki. Dzisiaj mniej lub bardziej zaawansowanych modeli używa większość zawodowych inwestorów i praktycznie każda instytucja.
Swoje modele mają banki inwestycyjne, fundusze hedgingowe, a nawet SEC, czyli amerykańska komisja nadzoru finansowego, która stosuje autorski model AQM (Accounting Quality Model). Po co? Żeby automatycznie analizować sprawozdania finansowe składane do SEC co kwartał w poszukiwaniu czerwonych flag mogących świadczyć o tym, że spółka manipuluje liczbami w swoim sprawozdaniu.
Większość istniejących modeli scoringowych powstała jednak po to, aby pomóc inwestorom rzetelnie oceniać i analizować najlepsze spółki do inwestycji, lub przynajmniej pomóc uniknąć kandydatów stojących w kolejce do bankructwa.
Wady i zalety gotowych modeli scoringowych
Pierwszy popularny model scoringowy, używany zresztą do dzisiaj, został zaproponowany w 1968 roku przez doktora finansów Edwarda Altmana z nowojorskiego uniwersytetu. Pierwotnym celem modelu było wykrycie sytuacji, w której spółka manipuluje danymi w swoim sprawozdaniu finansowym. Skuteczność modelu w tamtych czasach wynosiła 94%.
Potem Altman zmodyfikował nieco swoją formułę, aby większy nacisk położyła ona na przewidywanie prawdopodobieństwa bankructwa analizowanej spółki w ciągu kolejnego roku. Tu skuteczność nieco spadła, ale dalej wynosiła oszałamiających 80%.
Model Altmana (tzw. Altman Z-Score) jest używany do dzisiaj przez inwestorów, zwłaszcza że korelacja jego odczytów z późniejszym wzrostem kursu akcji została utrzymana i sprawdza się także obecnie.
Wybierając spółki do inwestycji z puli indeksu S&P 500 wyłącznie na podstawie oceny Altman Z-Score jesteśmy w stanie wypracować około 16% zysku średniorocznie vs. 10% zysk benchmarku.
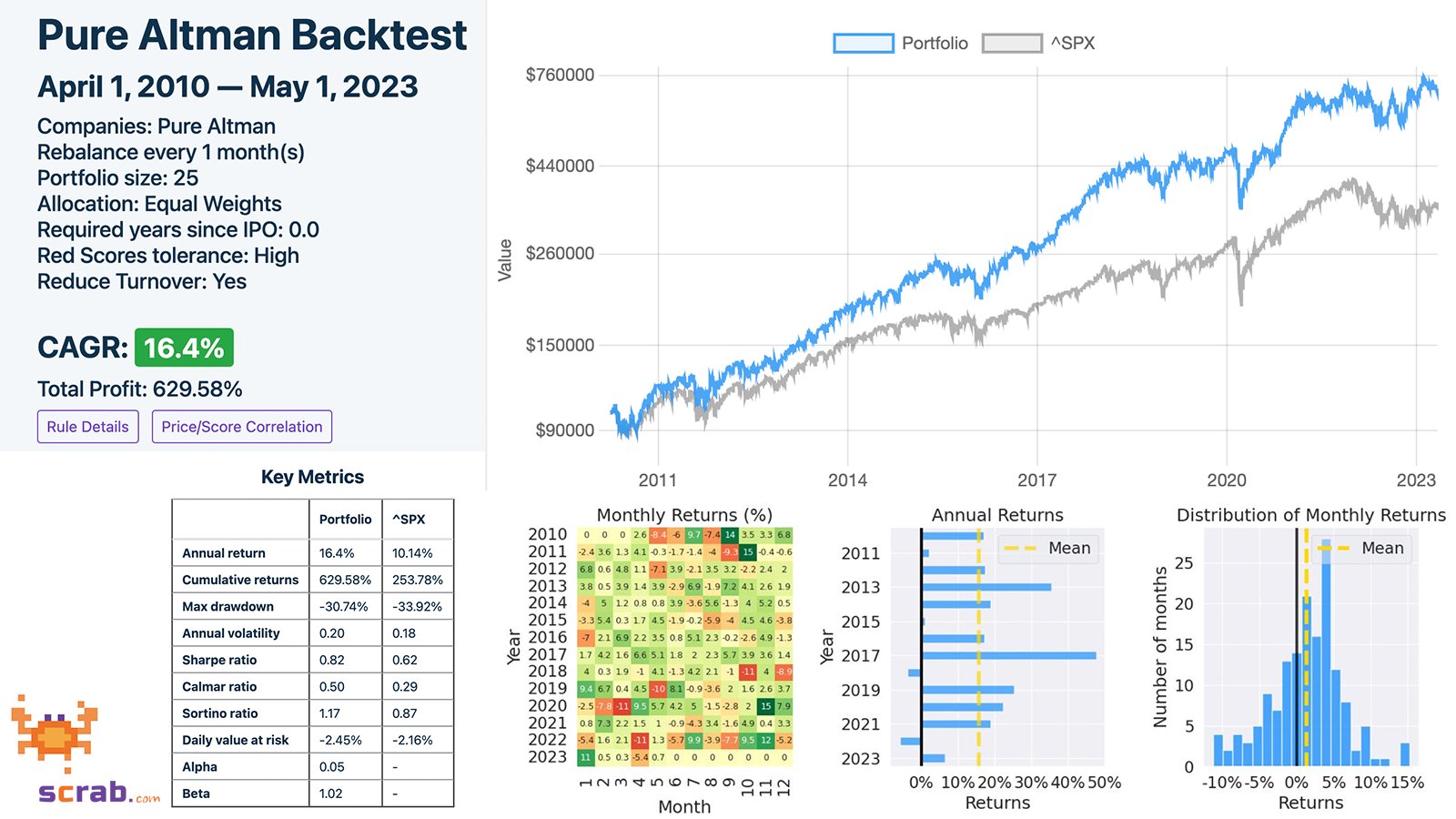
Model Altmana jest dość prosty. Wzór bierze pod uwagę stosunek wolnego kapitału, zysków, kapitalizację firmy oraz przychody i porównuje je do twardych aktywów spółki.
Edward Altman swoim modelem uruchomił lawinę podobnych wzorów. Jednym z bardziej popularnych, także stosowanych do dzisiaj, był kolejny model określający ryzyko bankructwa, zaproponowany w 1980 roku przez kolegę z tego samego uniwersytetu – Jamesa Ohlsona.
Ten jest już nieco bardziej skomplikowany i uwzględnia dodatkowo bieżącą płynność spółki czy gotówkę generowaną z działalności operacyjnej. Skuteczność modelu Ohlsona jest nieco wyższa niż w przypadku Altmana, ale nie jest on już tak prosty do obliczenia.
Podobnych wzorów było więcej. Jednymi z popularniejszych były bardzo proste (choć całkiem dobre), takie jak Sloan Ratio, czy nieco bardziej wysublimowane, jak Beneish M-Score albo popularny Piotroski F-Score czy formuła wyceny Petera Lyncha.
Do obliczenia niektórych początkowo wystarczyła kartka i kalkulator, co wymagało sporo pracy. Potem z pomocą przyszedł Excel ze swoimi formułkami, który mocno ułatwił życie. Cały czas jednak do Excela trzeba było przepisywać cząstkowe dane z aktualizowanych kwartalnie sprawozdań finansowych, co także okazywało się dość czasochłonne.
Dzisiaj większość dobrych serwisów analitycznych wskaźniki Altmana czy Ohlsona liczy już za nas automatycznie, ale… ma to niestety sporo wad.
Przede wszystkim każdy z gotowych modeli nastawiony jest na osiągnięcie jednego konkretnego celu i brakuje mu elastyczności. Ohlson ocenia ryzyko bankructwa, Beneish prawdopodobieństwo manipulacji w sprawozdaniu, a Piotroski ma mocne skrzywienie w stronę oceny niedowartościowania spółek.
Problem w tym, że spółka o niskim ryzyku bankructwa wcale nie musi być jednocześnie dobrą i perspektywiczną inwestycją. Firma która działa w nietypowej branży będzie miała nietypowe sprawozdanie finansowe, ale nie oznacza to manipulacji. Akcje wybitnie dobre nigdy nie będą wybitnie tanie, przez co ciężko będzie uzyskać wysoki scoring w modelu Piotroskiego.
Drugim problemem jest zerojedynkowość oceny w gotowych modelach scoringowych. Według nich spółka w danej kategorii może być albo zła albo dobra. Przykładowo, jeśli zyski rosną w tempie 5% rocznie, firma otrzymuje jeden punkt, a jeśli poniżej 5% – zero punktów.
W takim wypadku jeden punkt w ocenie otrzyma zarówno spółka, której zyski rosną w tempie 5.1% rocznie, jak w inna, której zyski rosną w tempie 50% rocznie.
Trzeci kłopot jest taki, że gotowe proste modele uwzględniają tylko kilka podstawowych parametrów fundamentalnych i brakuje im zniuansowania w ocenie.
W dodatku większość znanych modeli scoringowych powstała kilkadziesiąt lat temu do oceny firm produkcyjnych, które wtedy królowały na parkiecie. W tego typu tradycyjnych modelach zbyt duża wartość kładziona jest zatem na aktywa materialne (linie produkcyjne, fabryki etc.), a niejako karane są te spółki, których wartość bazuje na aktywach niematerialnych (know-how, patenty, ale też bazy danych o profilach użytkowników itd.).
To prawda, że stosując nawet te podstawowe modele, można dość prosto pobić benchmark o kilka punktów, ale… rozszerzając znane modele o dodatkowe parametry i kryteria, jesteśmy w stanie pobić benchmark nie o kilka, tylko o kilkanaście punktów procentowych.
Jak zbudować własny model scoringowy
Pierwszy krok to ustalenie listy parametrów, których ocena jest dla nas istotna.
Przykładowo: historyczne zyski i przychody z trzech ostatnich lat, prognozy zysków i przychodów na kolejne dwa lata, marża, zwrot z zainwestowanego kapitału, poziom zadłużenia, poziom płynności, poziom gotówki w kasie i tak dalej.
Następnie ustalamy dowolną skalę liczbową, która będzie zakresem minimalnej i maksymalnej oceny. Powiedzmy, że każdy parametr oceniamy w skali 1-10, czyli im gorsze wyniki, tym niższa ocena.
Na koniec sumujemy oceny poszczególnych parametrów i otrzymujemy łączny wynik każdej analizowanej spółki. Powtórzmy ten proces dla setki interesujących spółek, a następnie posortujmy je w dół od tej, która otrzymała największą łączna liczbę punktów i w ten sposób otrzymamy listę najlepszych akcji gotowych do inwestycji.
Proste, prawda?
Nie do końca. Pierwszy problem – to skąd mamy wiedzieć, który parametr fundamentalny jest istotny, a który nie? Nawet, jeśli ustalimy już, co konkretnie nas interesuje w ocenie spółki, to pojawia się drugi problem, a mianowicie – czy każdy parametr jest równie istotny?
Czy prognozy papierowych zysków powinny mieć taką samą wagę w ocenie jak prognozy realnej gotówki z działalności operacyjnej? Może gotówka jest ważniejsza, więc skala jej oceny powinna zostać utrzymana w zakresie 1-10, ale skalę oceny zysków powinniśmy zmniejszyć do 1-5?
Do tego dochodzi problem interpretacji danych, na które patrzymy. Czy prognozowany wzrost przychodów w wysokości 13% średniorocznie to dużo czy mało? Jaką punktację ze skali 1-10 należałoby tutaj zastosować? W dodatku, czy sam wzrost procentowy jest tak istotny?
A co jeśli dzisiaj spółka generuje zysk na akcję w wysokości 0.01$, a prognoza na kolejny rok wynosi 0.03$. Procentowy wzrost jest oszałamiający. Kto nie chciałby mieć w portfelu spółki generującej co roku zyski wyższe o 200%.
Tego typu problemy z interpretacją czystych liczb, bez kontekstu, można mnożyć, ale prawdziwy ambaras polega na tym, że tak naprawdę nigdy do końca nie będziemy wiedzieli czy nasz model zadziała w prawdziwym świecie.
Przetestowanie każdego modelu czy każdej hipotezy (większa czy mniejsza waga zysków?) będzie możliwe na prawdziwym rynku dopiero w perspektywie paru kolejnych lat.
A co jeśli model nie zadziała i wyniki będą gorsze niż wyniki całego rynku? Zmieniamy wtedy parametry i/lub wagi poszczególnych kryteriów, a potem zaczynamy całą zabawę od nowa? Za kilka lat otrzymamy kolejny feedback od rynku na temat tego, czy nas model pozwala pobić benchmark. A co, jeśli znowu nie?
Nikomu nie trzeba chyba mówić, jak bardzo ryzykowne, niewdzięczne i czasochłonne jest to podejście. Dlatego rozwiązania są dwa.
Przykładowy model scoringowy
Pierwsze rozwiązanie jest takie – można od kogoś kupić, ukraść lub wyprosić dobry model scoringowy, który ma już wieloletnią potwierdzoną skuteczność działania.
Tutaj mam dwie dobre wiadomości i jedną złą. Pierwsza dobra jest taka, że pod tym linkiem można pobrać przykładowy bardzo prosty model w Excelu, którego – z lekkimi modyfikacjami – sam używałem od lat. Na tym modelu pracowaliśmy zarówno w funduszu, jak i w trakcie ostatniego Uniwersytetu Inwestycyjnego.
Druga dobra wiadomość jest taka, że model działał, działa i pewnie długo jeszcze działał będzie. Poniżej zrzut z symulacją jego zachowania na przestrzeni ostatnich lat.
Na co patrzymy? Na prawie 800% potencjalnego zysku po dziesięciu latach vs. 212% zysku wypracowanego w tym samym czasie przez S&P 500.
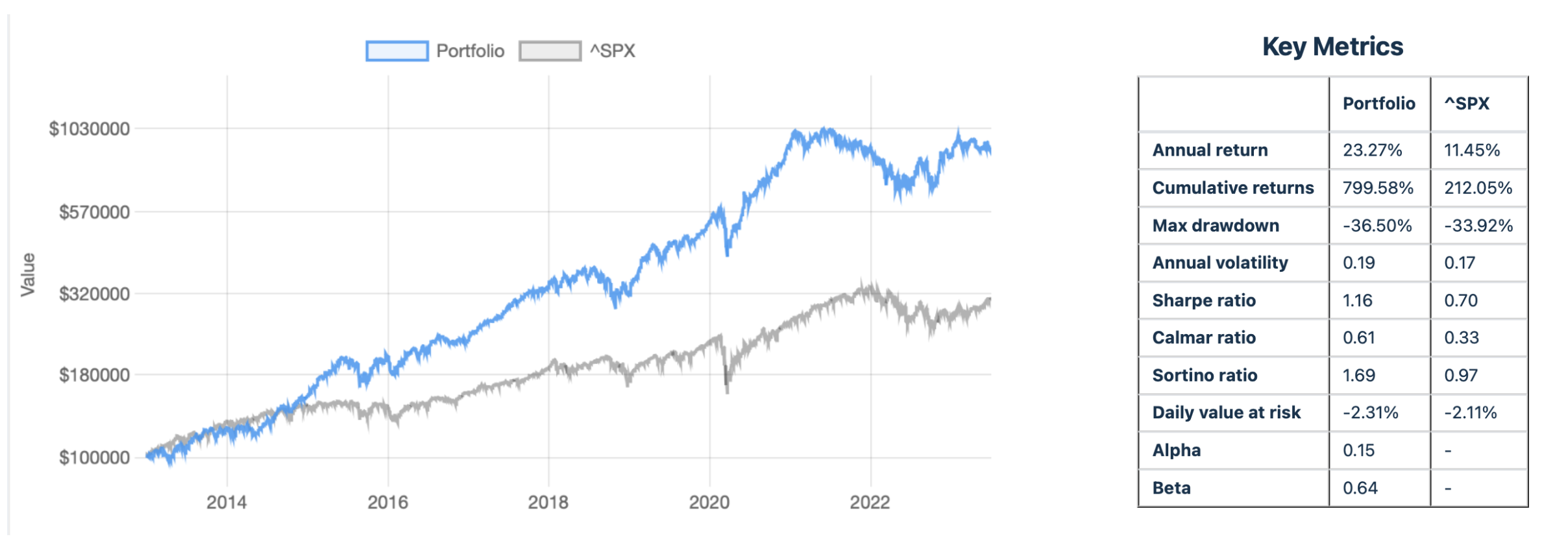
Zła wiadomość jest natomiast taka, że ciągle jest to model w Excelu, który wymaga ręcznego wpisywania parametrów, przynajmniej raz na kwartał, a idealnie raz na tydzień, aby zaktualizować dane o nowe prognozy, rewizje price targetów czy upside.
I tu na ratunek przychodzi drugie rozwiązanie, czyli… stworzenie własnych założeń, przetestowanie ich na wielu latach wstecz, a potem zautomatyzowanie całego procesu oceny.
Po co backtestować założenia? Aby upewnić się, czy mają jakikolwiek sens i czy pozwalają pokonać benchmark. Dzięki temu feedback o skuteczności modelu otrzymamy już po kilku minutach, a nie po kilku latach.
Problem z wieloma dostępnymi komercyjnie backtestami jest tylko taki, że pozwalają one backtestować portfolio złożone z konkretnych spółek wybranych dzisiaj, a nie testować same założenia inwestycyjne zamknięte w ramach modelu.
Z braku alternatyw sami stworzyliśmy zatem narzędzie pozwalające przeprowadzać najbardziej rzetelne backtesty z możliwych. Więcej o nich można poczytać na docsach SCRAB-a.
Co więcej, to samo narzędzie umożliwia zbudowanie od podstaw (lub wykorzystanie naszego) w pełni automatycznego modelu scoringowego, który przeprowadzi za nas całą robotę – od aktualizacji danych każdego dnia, po przygotowanie gotowej listy najlepszych spółek z całego świata.
Jak dokładnie, krok po kroku, wykorzystać taki model, pokazywaliśmy w trakcie dwugodzinnego SCRAB-owego webinaru, który można obejrzeć poniżej:
Bez względu na to, w jakiej formie będziemy korzystali z modelu scoringowego (ręcznej czy automatycznej), w zdecydowanej większości przypadków będzie to lepsze rozwiązanie niż opieranie się na własnej intuicji albo medialnych doniesieniach odnośnie poszczególnych spółek.
Tutaj można skorzystać z sekretnej oferty na Scrab, którego jestem ambasadorem w Polsce.

